, for everyone. More @ http://goo.gl/7AJzbL -->
<svg width="44" height="44" viewBox="0 0 44 44" xmlns="http://www.w3.org/2000/svg" stroke="%23F2EEEE">
<g fill="none" fill-rule="evenodd" stroke-width="2">
<circle cx="22" cy="22" r="1">
<animate attributeName="r"
begin="0s" dur="1.8s"
values="1; 20"
calcMode="spline"
keyTimes="0; 1"
keySplines="0.165, 0.84, 0.44, 1"
repeatCount="indefinite" />
<animate attributeName="stroke-opacity"
begin="0s" dur="1.8s"
values="1; 0"
calcMode="spline"
keyTimes="0; 1"
keySplines="0.3, 0.61, 0.355, 1"
repeatCount="indefinite" />
</circle>
<circle cx="22" cy="22" r="1">
<animate attributeName="r"
begin="-0.9s" dur="1.8s"
values="1; 20"
calcMode="spline"
keyTimes="0; 1"
keySplines="0.165, 0.84, 0.44, 1"
repeatCount="indefinite" />
<animate attributeName="stroke-opacity"
begin="-0.9s" dur="1.8s"
values="1; 0"
calcMode="spline"
keyTimes="0; 1"
keySplines="0.3, 0.61, 0.355, 1"
repeatCount="indefinite" />
</circle>
</g>
</svg>)


Chi non si è mai trovato nella situazione di dover scegliere un database per la propria applicazione e non sapere cosa fare? Ok, forse non molti, ma se stai leggendo questo articolo probabilmente stai cercando informazioni che portino un po’ di luce in questo mondo oscuro.
La scelta sicuramente non è semplice e le informazioni di cui tenere conto sono moltissime. Sarebbe bello se esistesse il database da consigliare, quello che va bene per tutte le applicazioni, ma purtroppo il mondo non è perfetto e quindi non lo sono neanche i dati. Con questa guida analizzeremo i vari passaggi da fare per individuare la giusta soluzione e proveremo a chiarire come affrontare al meglio ogni singola scelta.
Come prima cosa però bisogna individuare quali sono i propri requisiti di progetto.
Con che tipo di dati avrò a che fare? Quanti dati devo salvare? Che performance mi aspetto? Queste sono solo alcune delle domande da porsi e che saranno sviscerate nei paragrafi a seguire.
SQL vs noSQL
Prima di scendere nel dettaglio è necessaria una breve panoramica:
SQL è un linguaggio utilizzato per interrogare database relazionali, ma il termine si è esteso per indicare anche tali database. Al contrario, i database NoSQL hanno strutture diverse e non richiedono sempre l’uso di SQL per le interrogazioni.
Più avanti vedremo le differenze tra le due tipologie, ma per il momento ti basta sapere che:
Nei database relazionali, i dati sono organizzati in tabelle collegate da relazioni e interrogati con SQL. Nei NoSQL, i dati sono salvati in modi diversi e non sempre richiedono SQL per essere interrogati.
La scelta del DB da utilizzare dipende sempre dalle specifiche esigenze.
Cominciamo con il dire che no, i DB “classici” non sono ancora andati in pensione. Sicuramente i DB noSQL si sono imposti con una rapidità sorprendente e sono diventati un must in determinate situazioni, ma in alcuni casi i DB relazionali si difendono ancora molto bene e sono ancora da preferire.
Le domande da porsi per fare questa scelta sono principalmente tre:
- Che tipo di dati devo manipolare? Sono dati strutturati?
I DB relazionali sono pensati per salvare i dati in delle tabelle legate tra loro da relazioni. Quindi bisogna chiedersi se i dati sono strutturati, possono essere divisi in tabelle e i cui campi sono sempre gli stessi per tutti i record. - Quanto complesse sono le ricerche da fare sui dati? Prevedo di trovarmi spesso nella situazione di fare richieste complesse, che coinvolgono diversi campi e magari anche diverse tabelle?
- Ho bisogno di una consistenza forte dei dati? Cioè i dati devono sempre essere coerenti quando si effettuano letture e scritture in tempi molto ravvicinati, magari anche da processi diversi? I database relazionali rispettano le proprietà ACID ( Atomicità, Coerenza, Isolamento e Durabilità) che portano ad avere una forte consistenza dei dati sacrificando le prestazioni.
Se la risposta alle precedenti domande è affermativa (soprattutto l’ultima), allora la strada giusta è sicuramente quella di utilizzare un DB relazionale, altrimenti occorre virare verso il mondo dei noSQL.
Lo schemino!
Proviamo a razionalizzare i concetti di cui abbiamo parlato con il classico schema di confronto tra le due tipologie di database:
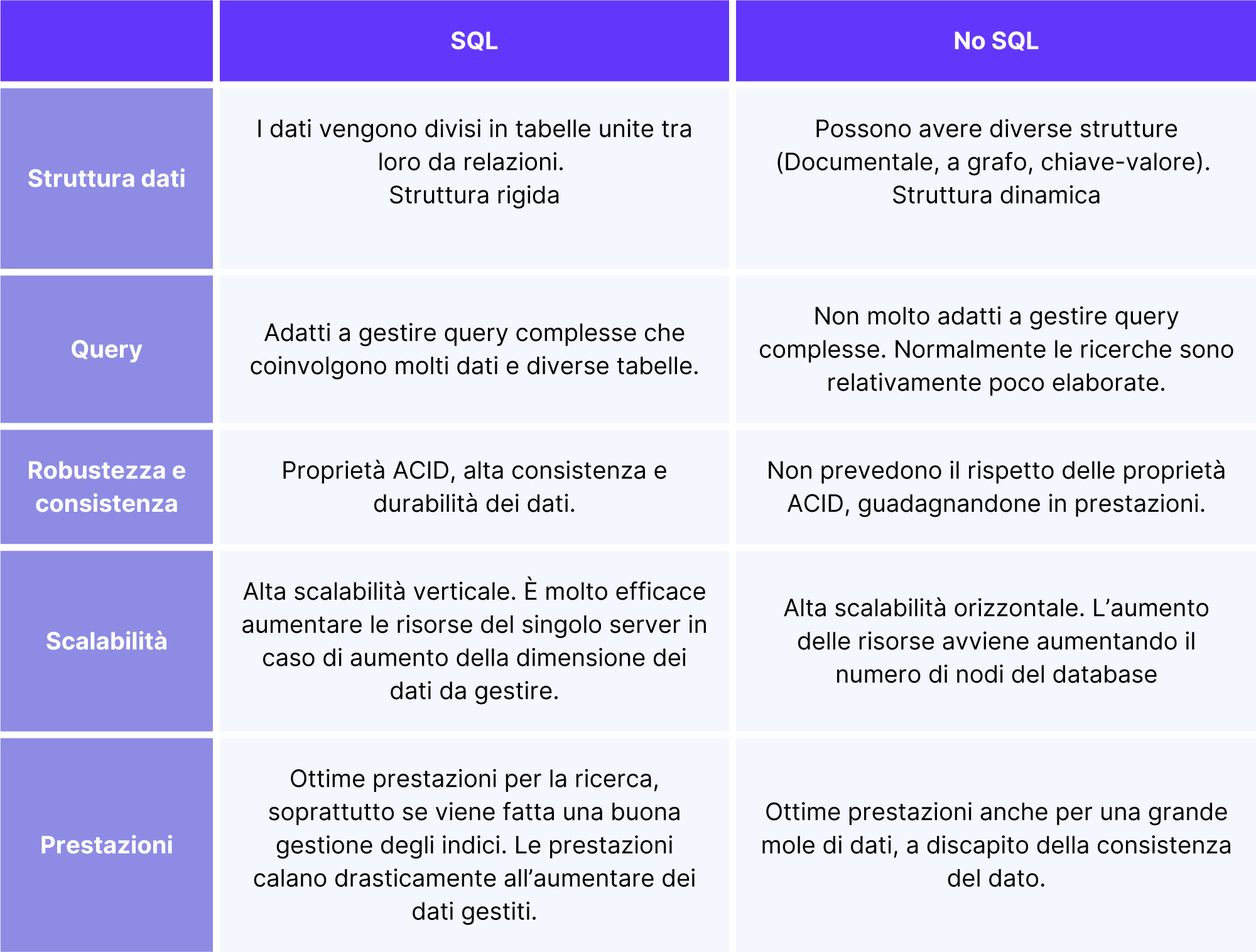
Facciamo qualche esempio pratico
Facciamo qualche esempio, in modo da provare a mettere in pratica i concetti appena espressi.
Ipotizziamo di dover creare un software di prenotazione voli per una compagnia aerea.
N.B. Ovviamente progettare e realizzare una vera applicazione di questo tipo è una cosa molto (molto, molto, molto) più complicata di come è qui descritto, ma rimane utile a titolo di esempio.
Dopo averci ragionato su capiamo che abbiamo tre entità importanti coinvolte: utenti, voli e prenotazioni.
Nel dettaglio:
- Utenti: id, nome, cognome, codice fiscale, data di nascita, ecc
- Voli: id, aeroporto di partenza, data di partenza, aeroporto di arrivo, data di arrivo, posti disponibili, costo.
- Prenotazioni: id, id utente, id volo
Ovviamente possiamo aggiungerne delle altre, come ad esempio Aeroporti, Aerei, Bagagli, ecc.
Un primo indizio che ci sarà utile nella scelta è che i dati sono totalmente strutturati. Tutti i record hanno le stesse colonne e di sicuro ci saranno pochissimi casi di campi vuoti (sono di sicuro quasi tutti obbligatori).
Per quanto riguarda le possibili query che ci servirà fare, a primo impatto sembrano semplici, ma se allarghiamo un po’ il dominio ci rendiamo conto che ci potrebbero essere parecchie join tra diverse tabelle. Pensiamo anche solo a quanto sarà utile prendere i dati di voli, aeroporti e aerei insieme durante la fase di prenotazione.
Valutiamo poi i requisiti di consistenza del dato, che di sicuro sono molto elevati. Ad esempio, dobbiamo essere certi di non salvare prenotazioni per voli già pieni, oppure non possiamo per nessun motivo perdere una prenotazione. Quindi serve avere le proprietà ACID.
Valutiamo adesso i requisiti di scalabilità. Abbiamo una compagnia aerea affermata, che ha un determinato traffico annuo che difficilmente varia in maniera significativa. Sicuramente il traffico e la richiesta di risorse può cambiare con il tempo, ma difficilmente si avrà la crescita esponenziale che può avere una startup o i picchi di utilizzo che può avere un sito che vende biglietti per i concerti. Probabilmente la variabilità può essere gestita modificando le risorse del database piuttosto che cambiando il numero di nodi. Se in più prevediamo un sistema di archiviazione delle prenotazioni relative a voli già conclusi, evitiamo anche il progressivo aumento del numero di dati nel corso del tempo.
Infine, dal punto di vista delle prestazioni, abbiamo sicuramente la necessità di fare ricerche specifiche e veloci (quando ad esempio l’utente deve cercare un volo o l’operatore deve cercare la prenotazione di un utente).
In questo esempio tutti gli indizi portano alla scelta di un database relazionale (l’esempio è chiaramente pensato ad hoc per ottenere questo esito). Dovremo certamente progettare una divisione in tabelle efficiente, degli indici adatti e un sistema di archiviazione che eviti la crescita indefinita del database.
Proviamo adesso a fare un altro esempio. Ipotizziamo di dover creare un’applicazione che permetta di collegare dispositivi per il monitoraggio di dati ambientali a un’applicazione in cloud (sensori di temperatura, di umidità, numero di persone presenti in una stanza, ecc…). L’obiettivo è quello di fornire ad aziende , privati o enti vari delle informazioni aggregate tra diversi dispositivi per ottimizzare la climatizzazione degli ambienti. In questa sede tralasciamo tutti i possibili problemi di sicurezza che si possono avere in un contesto come questo, ma ci concentreremo ovviamente solo sui dati. Come prima valutiamo punto per punto i requisiti di un’applicazione di questo tipo.
I dispositivi sono sicuramente di diversi tipi e di certo se ne possono aggiungere di altri tipi successivamente che non erano inizialmente previsti. Ognuno di questi dispositivi fornisce dati che possono essere totalmente diversi tra di loro, quindi sicuramente abbiamo a che fare con dati non strutturati.
Molto probabilmente non si dovranno fare molte ricerche o query sui dati, dato che non è importante tanto il valore puntuale di certi sensori, ma tutti i dati nel loro complesso e le loro evoluzioni. Saranno molto importanti anche le aggregazioni fatte sui dati e inoltre si può prevedere di dare in pasto questi dati a qualche algoritmo di intelligenza artificiale a cui affidare la gestione della climatizzazione degli ambienti.
Parlando della consistenza richiesta, non è necessario avere l’assoluta certezza che ogni dato sia salvato. Perdere qualche dato ogni tanto non comporta problemi, soprattutto se vengono fatte tante rilevazioni.
Al contrario la scalabilità è invece un requisito fondamentale. Ogni nuovo cliente porta nuovi dispositivi e un nuovo flusso di letture, quindi occorre adattare la nostra piattaforma a reagire e scalare quando necessario, e questo vale soprattutto per il db naturalmente.
Per la tipologia di applicazione più letture fanno i sensori, più precise saranno le misurazioni e quindi più efficaci saranno i risultati. Ne consegue che uno dei requisiti che deve avere il db è sicuramente quello di consentire il salvataggio di una grande quantità di dati, sia in generale che per unità di tempo. Va da sé che il tema delle prestazioni del db è di vitale importanza per la buona riuscita del progetto, è giusto preferire la velocità e la quantità di dati salvati alla consistenza del dato stesso, che non è di fondamentale importanza.
Per tutti questi motivi un database relazionale in questo caso farebbe da collo di bottiglia per tutto il sistema, costringendoci probabilmente a dover indefinitamente aumentare le risorse del db per stare dietro a sempre crescenti richieste. Strategia che a lungo andare sarebbe ovviamente fallimentare. I database noSQL in questi casi sono la scelta ottimale.
In questi esempi abbiamo trattato esclusivamente le differenze tra le due tipologie, ma in realtà anche database dello stesso tipo possono comunque avere delle differenze sostanziali che ci serve conoscere per fare la scelta adatta alle nostre esigenze.
DB relazionale: quale scegliere?
La scelta su quale DB relazionale puntare va fatta tenendo ben presente i punti di forza e di debolezza di ognuno. Le funzionalità non differiscono di molto tra un DB e un altro, quindi vanno valutati aspetti come costi, prestazioni in diverse condizioni, scalabilità, ecc.
Di seguito trovi una lista con i principali DB relazionali usati oggigiorno e le loro caratteristiche:
- PostgreSQL: è un DB open-source fortemente supportato dalla community e facilmente integrabile con diversi linguaggi di programmazione; supporta il formato JSON e il linguaggio PL/SQL. È molto usato grazie alle sue ottime prestazioni in relazione alla licenza open-source che garantisce bassi costi di gestione.
- MySQL: anche questo è gratuito e open-source, anche se esistono possibilità di supporto a pagamento. Molto apprezzato per le sue feature che garantiscono un’alta disponibilità del dato e la replica del db.
- Oracle: DB su licenza a pagamento, altamente scalabile e con funzionalità di sicurezza avanzate. Garantisce elevate prestazioni in caso di alti carichi di lavoro. Da preferire in caso di applicazioni di grosse dimensioni, che richiedono elevate prestazioni e facile scalabilità.
- Microsoft SQL Server: altro DB con licenza a pagamento, ma se si lavora in ambiente .NET, l’utilizzo di questo db è quasi obbligato; si integra perfettamente con le tecnologie Microsoft. Anche questo offre elevate prestazioni e scalabilità per applicazioni di grandi dimensioni; inoltre ha funzionalità avanzate di analytics.
E se mi serve un DB noSQL?
I database noSQL si differenziano tra di loro molto di più rispetto a quelli relazionali. Non ci sono solo differenze di funzionalità o prestazioni, ma spesso prodotti diversi hanno differenti modi di gestire e salvare il dato.
Orientati ai documenti
I DB documentali trattano i singoli record come documenti strutturati, tipicamente con formato JSON, XML o simili. Consentono una grande flessibilità, dato che ogni documento può avere una struttura diversa, a scapito delle prestazioni all’aumentare dei dati.
Esempi di questo tipo di DB sono i seguenti:
- MongoDB: uno dei DB più famosi, consente un’ottima scalabilità (soprattutto orizzontale), un ottimo sistema di indicizzazione e supporta query anche parecchio complesse. Tramite lo sharding si possono distribuire i dati su più nodi per migliorare le prestazioni. Da segnalare lo strumento delle aggregazioni che sono molto potenti per l’analisi dei dati.
- ElasticSearch: consente funzionalità di ricerca avanzate ed efficienti, anche questo è scalabile e distribuito. Ottima integrazione con Kibana, uno strumento open-source per la visualizzazione dei dati. È uno dei DB più usati per il salvataggio e l’analisi dei log delle applicazioni.
- CouchDB: sempre un db documentale con architettura distribuita, ma che pone una particolare attenzione alla consistenza del dato: fornisce diversi strumenti per il controllo della coerenza del dato e la gestione dei conflitti.
Chiave-Valore
Questi tipi di database hanno una struttura che associa ad una chiave valori di ogni tipo, anche i più complessi. Sono pensati per una facile partizione dei dati e sono ottimizzati per le operazioni di lettura e scrittura del dato. Raggiungono livelli di scalabilità orizzontale impensabili per ogni altro tipo di database.
Alcuni esempi di DB di questo tipo sono:
- Amazon DynamoDB: consente la scalabilità automatica in base alle esigenze momentanee dell’applicazione, si possono salvare anche dei documenti ed è perfetto per applicazioni serverless. Inoltre fa parte dell’ecosistema AWS, quindi si integra perfettamente a tutti gli strumenti Amazon.
- Redis: la caratteristica principale di Redis è il salvataggio dei dati in memoria, il che lo rende adatto per applicazioni che richiedono alte prestazioni. Ovviamente supporta anche la persistenza dei dati tramite backup.
Database a colonne
Sono database progettati per gestire grandi volumi di dati distribuiti. I dati vengono memorizzati con struttura tabellare con colonne flessibili. In pratica non tutti i dati di una tabella hanno le stesse colonne, ma ogni dato avrà i riferimenti alle colonne da utilizzare.
I db usati maggiormente con questa struttura sono:
- Cassandra: ha un’architettura distribuita, che evita il single-point-of-failure e quindi ha un’alta tolleranza ai guasti. È adatto per quelle applicazioni che richiedono prestazioni elevate e alta disponibilità dei dati.
- HBase: supporta operazioni atomiche ed è compatibile con l’ecosistema Apache Hadoop.
Database a grafo
Questi database utilizzano la struttura a grafo per memorizzare le relazioni tra nodi, in modo da identificare e analizzare le connessioni tra i dati salvati. I dati e i parametri delle relazioni tra nodi sono importanti tanto quanto i dati in sé, se non di più. Vengono spesso usati per fare analisi come attraversamento del grafo, percorso più veloce, ecc.
Il database di questo tipo di gran lunga più utilizzato è:
Neo4J: fortemente integrato con i linguaggi di programmazione più comuni, questo è un database che offre ottima scalabilità orizzontale, transazioni ACID e garantisce un’alta disponibilità del dato grazie alle repliche su più nodi. Inoltre offre diverse estensioni e plugin che permettono diverse funzionalità e l’integrazione con diversi sistemi e tecnologie.
Conclusioni
In conclusione, la selezione del database per un’applicazione è una decisione cruciale che può influenzare significativamente il successo del progetto. Ogni database ha le proprie caratteristiche distintive, suggeriamo pertanto di considerare sempre in modo attendo le esigenze specifiche del progetto di modo da raggiungere il miglior risultato possibile.
Questo articolo prova a fornire chiarezza e orientamento, offrendo concetti utili per guidare la scelta del database più adatto provando a fornire informazioni che possano aiutare a compiere una delle decisioni più importanti nel processo di sviluppo software.

